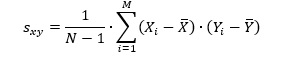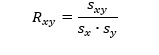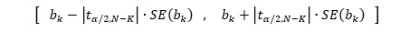Det nærmer seg eksamen i MET3590 – metode og økonometri. Hvert semester får jeg veldig mange spørsmål om gamle eksamensoppgaver, særlig knyttet til caseoppgavene.
Jeg har derfor laget et meget omfattende 498-siders eksamenskompendium som består av alle eksamensoppgavene knyttet til caset for de siste 17 eksamenene (altså fra høst 2011 til høst 2019). Dette dokumentet inneholder altså i overkant av 250 oppgaver med løsningsforslag i tillegg til caseløsninger for caset i hver eksamen. Hver oppgave har et løsningsforslag med henvisning til riktig formel og/eller hvor i modellene fra caseløsningen man finner svaret. Du vil med andre ord ikke bare få en oversikt over hvilke svar som er riktig, men forklaring på hvordan du kommer frem til riktig svar. Du får også noen tips og triks underveis som kan være hjelpsomme å ha i bakhodet til eksamen. Merk at dokumentet kun tar for seg eksamensoppgavene knyttet til caset (altså typisk de første 15 oppgavene på eksamen).
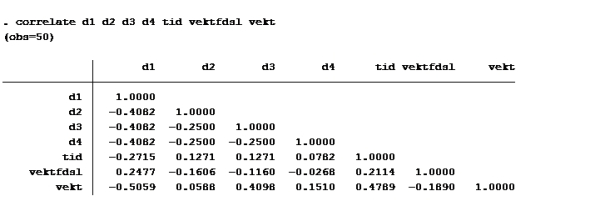
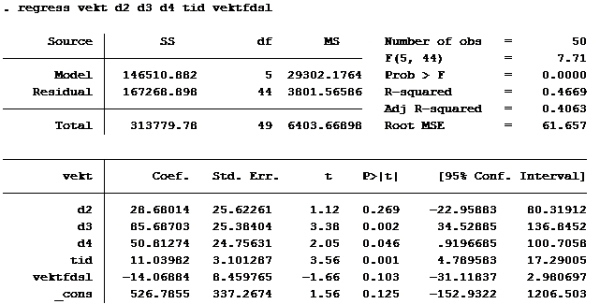
Lag dummyvariabler: gen d1=fortype==1 gen d2=fortype==2 gen d3=fortype==3 gen d4=fortype==4
B: Korrelasjonsmatrise:
1)
2)
C:
D:
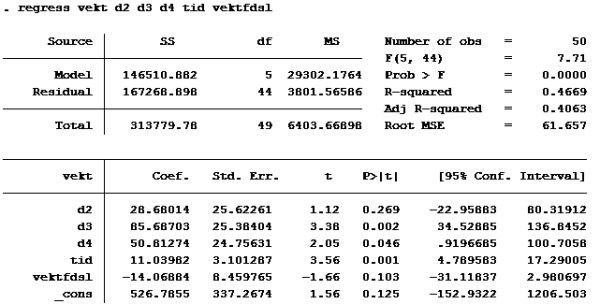
E: T-test: En t-test brukes til enkel hypotesetesting. Det vil si at man bare tester én koeffisient av gangen. Nullhypotesen i en t-test er gitt ved likhet, dvs. at koeffisienten det er snakk om antas å være lik en viss verdi. Enkelt kan vi bare se på P>|t|. De variablene med p>|t| over 0,05 skal ut. Det betyr at d2 og vektfdsl skal ut.
Da får vi:
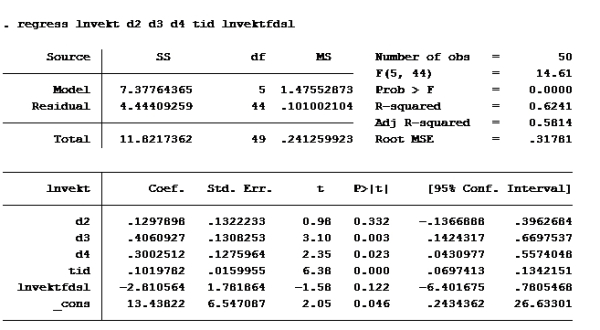
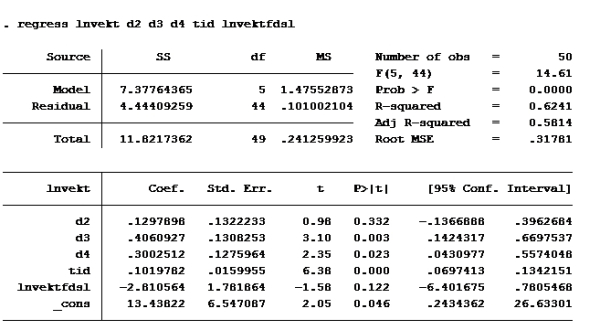
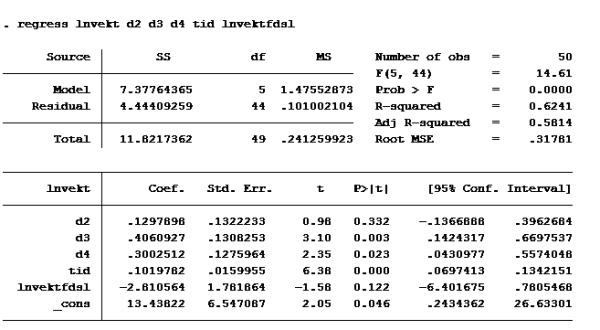
F: Vi må generere en variabel med den naturlige logaritmen til vekt og vektfdsl: Det gjør vi ganske enkelt med kommandoene: gen lnvekt=ln(vekt) gen lnvektfdsl=ln(vektfdsl)
Deretter kjører vi regresjonen de ber om:
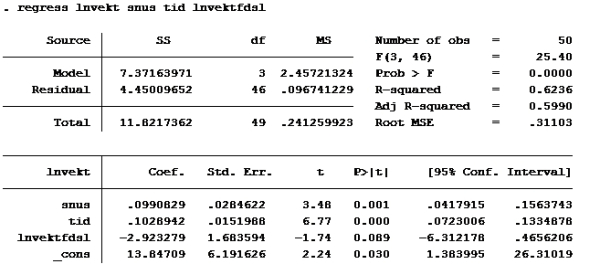
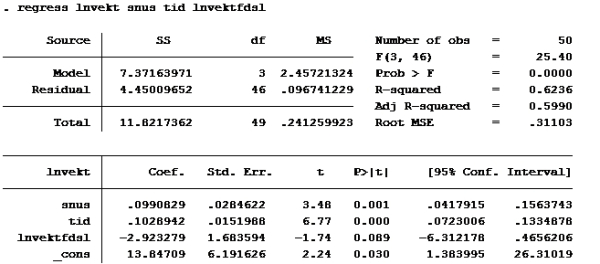
G: Lager først ny variabel med (d2+4*d3+3*d4). Kaller den bare «snus», fordi det er gøy.
gen snus=d2+4*d3+3*d4
Kjører deretter regress:
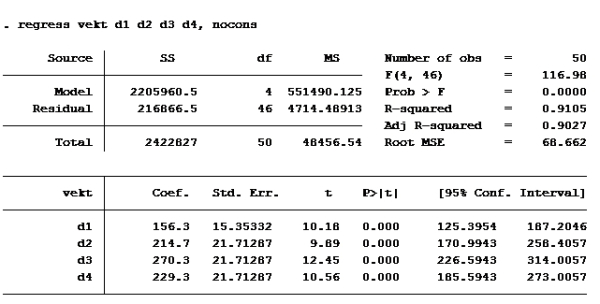
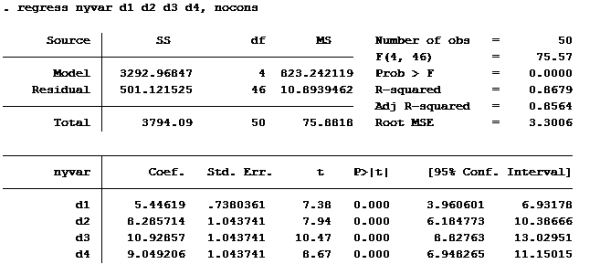
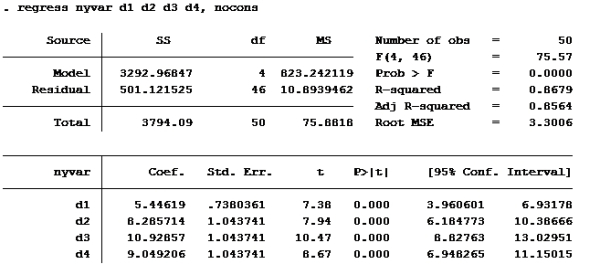
H: Lager den nye variabelen de ber om. Kaller den “nyvar” gen nyvar=(vekt-vektfdsl)/tid
Kjører deretter regresjon med suppressed cons (nocons):
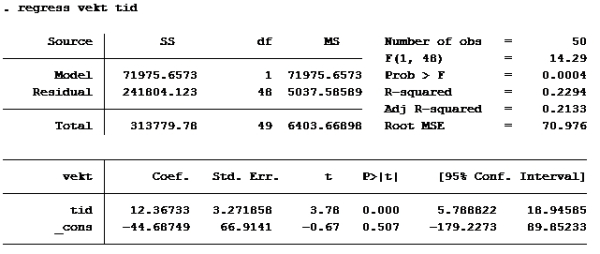
Da var det gjort. Så var det oppgavene: Oppgave 1: Her er det et spørsmål om variablenes målenivå. Det at variablen er på forholdsnivå (skalanivå) betyr at en i tillegg til å rangere og måle f.eks avstand også kan beregne forholdstall. For eksempel er variabelen inntekt på forholdstallsnivå. (Noen som tjener 200 000 har dobbelt så stor inntekt som noen som tjener 100 000). Vekt og tid kan også måles som forholdstall, mens fôrtype ikke kan det. Riktig svar er d
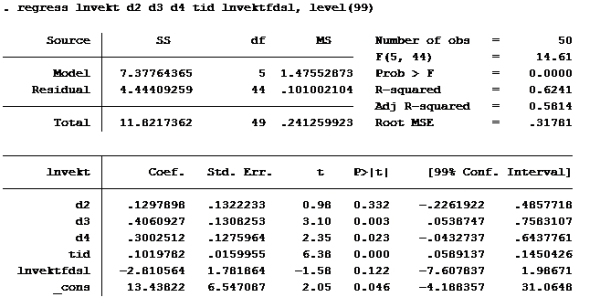
Oppgave 2: Kjører ny regresjon med 99% konfidensintervall:
Her ser vi at konfidensintervallet til lnvektfdsl er [-7,607837; 1,98671]
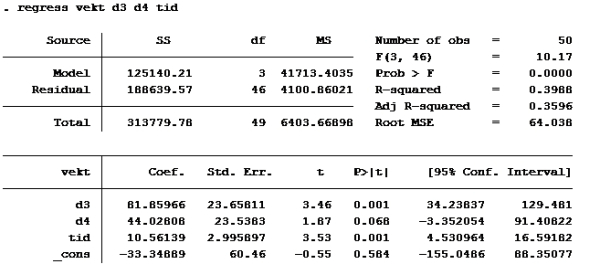
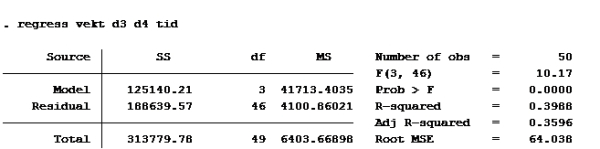
Her må vi se hvilken modell som har høyest forklaringskraft (uttrykt ved r-squared) a)
b) c) d)
Som vi ser har modell d) høyest r-squared.
Alternativ d er riktig
Oppgave 4 Modell D igjen:
Som vi allerede så er d2 og vektfdsl ikke signifikante på 5% nivå. (P>|t| er større enn 0,05). De andre er det. d4 er imidlertid ikke signifikant på 1% nivå (P>|t| er større enn 0,01 på d4) Alternativ b er riktig.
Oppgave 5: Modell H
Bare se på koeffisienten til d4, den er ca 9.
alternativ d er riktig
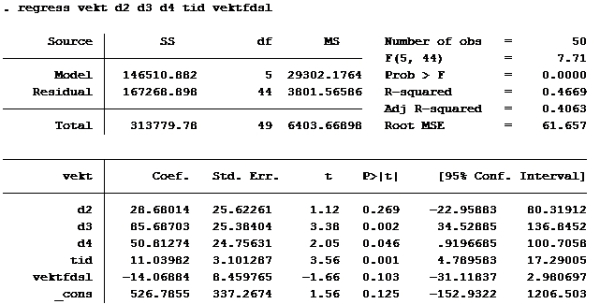
Oppgave 6 Modell F
Her må du pålegge modellen følgende restriksjoner: B3 = 4B2 og B4 = 3B2 Fordi: Hvis vi løser opp parentesen B2(d2+4d3+3d4) får vi: B2*d2 + 4B2*d3 + 3B23*d4
Regresjonen er egentlig: ln(vekt) = B1 + B2*d2 + B3*d3 + B4*d4 + B5*tid + B6*lnvektfdsl –>Setter inn 4B2 for B3 og 3B2 for B4: ln(vekt) = B1 + B2*d2 + 4B2*d3 + 3B2*d4 + B5*tid + B6*lnvektfdsl
Alternativ b er riktig.
Har du nytte av bloggen? Vipps en kaffekopp eller et valgfritt beløp:
Sjekk der det står residual. Der står det 4,444 på modell F og 4,4500 på modell G Benytter F-test (multippel hypotesetesting, som innebærer at man tester flere koeffisienter av gangen).
testobservator finner vi ved: (RSSmed – RSSuten) / m) / ((RSSuten / (N – K )) hvor m er antall hypoteser/restriksjoner, N er antall observasjoner og K er koeffisienter i regresjonsmodellen (uten restriksjoner) RSSmed er RSS med restriksjoner, og RSSuten er RSS uten restriksjoner. RSSmed er det du får når du kjører modellen med «snus» (altså modell G), da den pålegger modellen restriksjoner.
RSS uten er det du får når du kjører uten restriksjoner, altså lnvekt d2 d3 d4 tid lnvektfdsl
Vi har jo følgende tall: N er 50 (50 observasjoner) K er 6 (6 Ber) m: 2 (2 restriksjoner, B3 = 4B2 og B4 = 3B2) RSSmed er 4,45009652 RSSuten er 4,44409259
Slå opp i tabellene på 1%, 5% og 10% signifikansnivå og se på m=2 og N-K = 44 (i tabellen er ikke 44 med, men se på 40) for å se om noen av verdiene der er lavere enn 0,0297218065. Er de lavere, forkastes nullhypotesen. Jeg får henholdsvis verdiene 5,18, 3,23 og 2,44 . Ingen av dem er lavere enn testobservator, som betyr at nullhypotesen ikke forkastes på noen av de tre signifikansnivåene.
Riktig alternativ er a
Oppgave 8 Modell D:
Setter inn: B2=0 B3=1, B4=0, B5=21, B6=41,06: 526,7855 + 28,6801*0 + 85,6870*1 + 50,8127*0 + 11,0398*21 – 14,06884*41,06 = ca 267 Alternativ c er riktig
Oppgave 9
Modell E Setter inn: B2=1, B3=0, B4=21 -33,3489 + 81,8597*1 + 44,0281*0 + 10,5614*21 = ca 270 Alternativ c er riktig
Oppgave 10: Hvis vi ser på regresjonene for C, D og E ser vi at koeffisienten til d3 er den som er størst (positiv). Det vil med andre ord si at effekten er størst for fôrtype 3. Eks: Alternativ c er riktig her også
Oppgave 11: Her er det en lineær sammenheng Endring Y = endring B2*endring X
Bare test: Yhatt = 1,08 + 0,19X2 + 33,64lnX3 + 68,11 Dersom vi øker C2 med én enhet, og lar alle de andre X-ene være uforandret ser vi at Yhatt vil øke med 0,19. De andre alternativene er derfor sikkert feil.
Alternativ d er riktig Oppgave 12 Lin-log (Lineær venstreside, logaritme på høyreside) Vi ser at ved endring på 1%: Endring Y = B3*1% Endring Y = 33,64*0,01=0,3364 Alternativ c er riktig
Oppgave 13: Resiprok-modell: Endring Y = 68,11*(1/11) – 68,11*(1/10) = -0,60818 For å se endringen ved økning fra 10 til 11 Alternativ a er riktig
Oppgave 14 Dersom man setter alle koeffisientene lik 0 vil alltid R^2 være 0. Logikken er at R^2 er forklaringskraft, dersom man setter alle de uavhengige variablene lik 0, slik at regresjonsmodellen bare inneholder konstantleddet vil ikke modellen ha noen forklaringskraft. For den som vil ha litt mer kjøtt på beinet her: R^2 kan regnes ut ved: 1 – (RSS/TSS). Hvor RSS er residualsummen og TSS er totalkvadratsummen. Når regresjonen KUN inneholder konstantleddet kan det vises at RSS = TSS, altså at RSS/TSS = 1, og at R^2 = 1-1= 0. Fun fact: selv om R^2 er «opphøyd i andre», betyr ikke det at R^2 ikke kan være negativ. I enkelte tilfeller, hvor konstantleddet ikke inkluderes kan faktisk R^2 være negativ. Dette betyr at man har «negativ forklaringskraft». Sjukt å melde?
Oppgave 15: Vi bruker F-testen for multippel hypotesetesting og finner kritiske verdier for signifikansnivåene: *3 restriksjoner (m) *44 observasjoner (N) *4 koeffisienter uten restriksjoner(K)
Ser i F-tabellene: F1%, 3, 44-4 = 4,31 F5%, 3, 44-4 = 2,84 F10%, 3, 44-4 = 2,23
Det betyr at alternativ d må være riktig.
Oppgave 16 Ser i F-tabellene: F1%, 3, 44-4 = 4,31 F5%, 3, 44-4 = 2,84 F10%, 3, 44-4 = 2,23 Hvis testverdien i forrige oppgave er 2,839 ( altså ca 2,84) er p-verdien ca 5% Alternativ b er riktig
Her skal jeg innrømme at jeg er litt usikker på svaret, men regelen er jo at når H0 forkastes, så har vi grunnlag for å hevde at det er lineær samvariasjon mellom den uavhengige variabelen og den avhengige variabelen. Konklusjonen blir derfor så vidt jeg kan forstå at det er en lineær sammenheng mellom X og Y.
Alternativ c er riktig (tror jeg)
Oppgave 18
Dersom vi har en kvalitativ variabel med m ulike verdier, kan vi IKKE inkludere konstanten B1 dersom vi skal inkludere m dummyvariabler. Dersom vi har en kvalitatativ variabel med m ulike verdier, kan vi inkludere konstanten B1 dersom vi kun inkluderer m-1 dummyvariabler
Alternativ d er riktig fordi der har de m dummyvariabler + konstantledd.
Testverdien (R^2uten – R^2med) / m) / ((1-R^2 uten/ (N – K )) R^2 med restriksjoner vil være 0 når bare konstantleddet står igjen. Testverdi = ((0,08 – 0)/2) / ((1-0,08)/65) Testverdi = 2,82
Konklusjonen blir at på signifikansnivåene 1% og 5% beholdes H0 om at gjennomsnittlig antall klikk kan være lik for de tre reklamene (fordi testverdi er mindre enn kritisk verdi). På et 10% signifikansnivå forkastes derimot H0.
Første arbeidskrav i metode og økonometri er ute, og kanskje har dere allerede bestått med glans. For de som ikke har det: la oss finne ut av dette sammen. Siden dere ikke har nummeret mitt, og ikke kan vippse meg penger, får dere heller legge igjen en kommentar hvis dere syns dette er et innlegg du setter over gjennomsnittet pris på (eller verdsettelse-strek som vi sier i dette faget, hehehehehehehehehehehe.) Har ikke orket å lese over innlegget, så si ifra hvis du finner noen feil også.
I dette arbeidskravet skal vi blant annet se på en rekke forhold på arbeidsplassen (uavhengige variabler) og hvordan de utgjør den samlede poengsummen (indeksen) som uttrykker hvor fornøyd de ansatte er med sjefen sin (Y).
I oppgave 1-10 i arbeidskravet har vi X uavhengige variabler (X2, X3… X7). Så det vi ønsker å finne ut fra en regresjonsanalyse er å finne ut f.eks hvor mye, og i hvilken retning, en endring i X2, som i vårt tilfelle er prosentandelen ansatte som mener sjefen ikke forskjellsbehandler de ansatte, påvirker Y (den avhengige variablen).
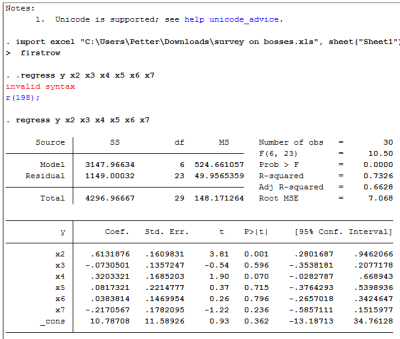
Det første jeg gjør er å importere excel-arket “survey on bosses” i Stata, og kjører en regress på modell (1). Dette gjør du ved å skrive “regress y x2 x3 x4 x5 x6 x7” i command-linja. Da kjører du en regresjon på modellen: Y = B1 + B2x2+B3x3… +B7x7 + u
I oppgave 1 skal vi finne den estimerte effekten på tilfredsheten med klage-håndtering. Det du må se etter da er B2, altså “Coef.” til x2. Den ser du er 0.6131876.
I oppgave 2 skal du ta utgangspunkt i beregningen til modell 1, og se hvilken av de 4 tolkningene som er korrekte. Spørsmålet er knyttet til x3, altså forskjellsbehandlingen. Her er det viktig å merke seg den negative sammenhengen mellom den uavhengige variablen x3 og den avhengige variablen. Det kan med andre ord se ut som at dersom antallet som mener sjefen ikke forskjellsbehandler stiger, så synker tilfredsheten noe (0,07305), gitt at de andre uavhengige variablene forblir uendret.
I oppgave 3 blir du bedt om å finne residualkvadratsummen (RSS – Residual Sum of Squares). Den finner du der det står “residual” og under SS. Altså 1149,00.
I oppgave 4 skal du også ta utgangspunkt i modell 1, og svare på hvor mye av variasjonene i indeksen for tilfredsheten med sjefen som forklares av modellen. Det er det vi kaller forklaringskraft, og den regnes ut ved (1 – (RSS/TSS)). RSS fant du i oppgave 3, og TSS er “total”, altså 4296,96667. Den er også regnet ut i modellen. Da må du se på R-squared. Den sier 73,26%.
I oppgave 5 skal vi se på generell tilfredshet på jobben. De variablene som har med de ansattes forhold til sjefen å gjøre basert på generell tilfredshet er x2, x3 og x6. Derfor må du kjøre en regress på de variablene. Da får du en ny RSS (RSSmed) som er 1361,80481. RSSuten har du fra før, for den fant du i oppgave 3. Så bruker du denne formelen for å finne testobservator: ((RSSmed – RSSuten) / m) / ((RSSuten / (N – K )) hvor m er antall hypoteser/restriksjoner, N er antall observasjoner og K er koeffisienter i regresjonsmodellen (uten restriksjoner) ((1361,8004 – 1149 ) / 3) / (1149 / (30 – 7)) = 1,42
I oppgave 6 må du slå opp i tabellene på 1%, 5% og 10% signifikansnivå og se på m=3 og N-K = 23 for å se om noen av verdiene der er lavere enn 1,42. Er de lavere, forkastes nullhypotesen. Jeg får henholdsvis verdiene 4,76, 3,03 og 2,32. Ingen av dem er lavere enn 1,42, som betyr at nullhypotesen ikke forkastes på noen av de tre signifikansnivåene.
I oppgave 7 gjør du samme prosess, men med X2, X3 og X6 satt lik null, slik at du kjører regress på X4, X5 og X7
((RSSmed – RSSuten) / m) / ((RSSuten / (N – K ))
((1923,42417 – 1149) / 3) / (1149 / 23) = 5,17
I oppgave 8 sjekker du tabellene igjen, og ser om noen av verdiene er lavere enn 5,17. Igjen, jeg får henholdsvis verdiene 4,76, 3,03 og 2,32. Alle av dem er lavere enn 5,17, hvilket betyr at nullhypotesen forkastes ved alle de tre signifikansnivåene.
I oppgave 9 kjører du en regress på bare x2.
((1369,38241 – 1149) / 5) / (1149 / 23) =0,882
Sjekker du m=5 N-K =23 i tabellen får du henholdsvis 3,94, 2,64 og 2,11. Ingen av dem er lavere enn testobservatoren – ergo nullhypotesen forkastes ikke hvis vi bruker et signifikansnivå som er 10% eller lavere.
I oppgave 10 mener jeg det er åpenbart at man bør iverksette tiltak som bedrer sjefens håndtering av ansatteklager, ettersom vi ikke kan forkaste hypotsenen om at dette alene betyr noe for tilfredsheten med sjefen.
I oppgave 11 skal du finne utvalgskovariansen mellom NO2 og CAR. Vi vet at utvalgskovariansen finnes slik: Men, vi kan også finne den ved å snu om på formelen for utvalgskorrelasjon (som vi har fått oppgitt). Sx og Sy (Sno2 og Scar) er kvadratrota av de to variansene. 034 = X / rot(1903,84) * rot(1,31) 0,34 = X /43,6330 * 1,1445523 0,34 = X / 49,94 X = 16,98
Oppgave 12: Med utgangspunkt i denne informasjonen kan vi beregne modellen: NO2 = B1 + B2CAR + u slik: For å beregne B2 bruker du B2 = Cov(CAR,NO2) / Var(CAR). Cov fant du i forrige oppgave. Variansen er gitt i den innledende oppgaveteksten (1,31)
16,98/1,31 = 12,96CAR
Deretter finner du B1 ved: B1 = NO2-strek – B2*CAR-strek | hvor jeg med strek mener gjennomsnitt (som er gitt i innledende oppgavetekst)
Altså B1 = 52,11 -12,96*1,63 = …
I oppgave 13 skal du finne R^2. Du har oppgitt R (utvalgskorrelasjonen), så bare opphøyd den i andre.
I oppgave 14 skal du finne justert determinasjonskoeffisient
Den finner du ved: 1-(1-R^2) * ((N-1)/(N-K)) | hvor N er antall observasjoner og K er antall regresjonskoeffisienter Med andre ord: R^2justert = 1- (1-0,1156) * (63-1) / (63-2) = …
I oppgave 15 skal du bruke modellen du laget i oppgave 12 til å beregne NO2 for 1,63CAR. Da bare legger du inn verdien 1,63 slik at du får 30,99 + (12,96*1,63) = …
I oppgave 16 skal du regne konfidensintervallet. Du vet at stigningstallet er 12,96 jfr oppgave 12. Bruk den som bk i formelen: Bruk tabell for t-fordeling (60 frihetsgrader) Da burde du få noe slikt: [12,96 – (2,00*4,59) , 12,96 + (2,00*4,59)]
Regn ut, og finn rett svar!
I oppgave 17 går jeg inn i tabellen, på 18 frihetsgrader, og ser at 1,330 ligger på 20%, altså er svaret 80% sannsynlighet for at testverdien ligger i intervallet.
I oppgave 19 slår vi opp i tabellen på 40 frihetsgrader ( fordi vi har 2 B-er, dvs k=2, og frihetsgrader er (n-k) = 42-2=40. Vi finner 1,3 på 20%.
I oppgave 20 må vi forstå hvordan vi finner ut antall Xer. Antall Xer er én mindre enn antall Ber. Antall B-er uttrykkes som k, og frihetsgrader uttrykkes som n-k Med andre ord får vi nok en ligning her. Jeg stikker mitt usedvanlig velstelte ansikt inn i tabellen for en ensidig test (fordi her har vi bare én side, vi skal sjekke om B2 er større enn null). Jeg finner ut at med 5% signifikansnivå er 23 frihetsgrader gir vår kritiske verdi på 1,714. Det vil altså si at:
n-k = 23 n er gitt som 27 som gir oss en sjukt i hue jævlig enkel ligning: 27-k = 23 k=4
Som jeg sa var k lik antall B-er, og antall Xer er (k-1) 4-1 = 3 skulle jeg mene.
Gratulerer. Du har nå bestått arbeidskrav 1 med 100% riktige svar.
Har du nytte av bloggen? Vipps en kaffekopp eller et valgfritt beløp: